Lojban Wave Lessons/All about sumti
Lesson 14: Lojban sumti 1ː LE and LA
If you have read and understood the content of all the lessons until now, you have amassed a large enough knowledge of Lojban so that it doesn't matter in which order you learn the rest. As a result, the order of the next lessons will be a mixture of sorted by increasing difficulty and sorted by importance in ordinary Lojban conversation.
One of the biggest constrains on your speak now is your limited knowledge on how to make sumti. So far, you only know ti and lo SELBRI, which doesn't take you far considering how important sumti are in Lojban. This lesson as well as the following two will be about the Lojban sumti. For now, we focus on the descriptive-like sumti, the ones made with articles like lo
Articles are in lojban called gadri, and all the ones discussed in this lesson are terminated by ku, except the combination LA CMEVLA. We will begin by describing three simple kinds of descriptive sumti, and then immediately find that they are not so simple after all:
- lo = gadri: generic, converts selbri to sumti.
- le = gadri: specific and descriptive, converts selbri to sumti.
- la = gadri: naming article, convert selbri or cmevla to sumti.
You are already familiar with lo and what it does. lo creates a sumti referring to what fits in the first place of the following selbri.
This may be contrasted with le, which is specific and descriptive. Saying le gerku says that you have one or more specific objects in mind, and you use the selbri gerku to describe it, so that the listener may identify those specific objects. This means that le has two important differences from lo: Firstly, it cannot refer to objects in general, but always refers to specific objects. Secondly, le gerku explicitly hints that the selbri is only meant to help the speaker identify what the description refers to, whether or not it actually satisfies the selbri. Perhaps the speaker is referring to a hyena, but is not familiar with them and thinks dog is a good enough approximation to be understood; however, this non-veridicality is perhaps over-emphasized in many texts. The best way to describe a dog is usually to describe it as being a dog, and unless there is a good reason not to, le gerku is usually presumed to refer to something which is also lo gerku.
In translation, lo gerku can be any of the dog, the dogs, a dog, some dogs, or dogs in general, while le gerku is the dog or the dogs. Even better for le gerku would be the dog(s)
Last of the three basic gadri, there is la, the naming gadri, which strips the following selbri of its usual meaning and refers to someone or something whose name is that selbri. If I in English refer to a person called Innocent by her name, I neither describe her as being innocent, nor do I state that she is. I only state that by convention, that object is referred to by that selbri or cmevla. Note that la and the gadri derived from it can convert cmevla to sumti unlike any other gadri. Also: Be cautious: Other texts do not mention that names can be formed from ordinary selbri using the gadri la. But those heretics must burn; selbri names are as good as they get, and many a proud Lojbanist have them.
la is a bit eccentric, since it always marks the beginning of a name. Unlike the other gadri, anything that can be grammatically placed after la and its sisters are considered part of the name. For example, le mi gerku is "my dog", but la mi gerku is someone or something called "My Dog".
These three basic gadri can be expanded with three more, which correspond to the previous:
- loi = gadri: generic, mass of individuals
- lei = gadri: specific and descriptive, mass of individuals
- lai = gadri: mass of named individuals
These are the same as the first three articles in all aspects except for one: they wrap the sumti into masses. Masses are used to abstract multiple individuals into single entities for ease of expression. For example, a football team can be described as a mass of its members, or an animal as a mass of cells.
- mivysle = x1 is a biological cell of organism x2
- remna = x1 is a human
loi mivysle cu remna - "Masses of cells are humans". Again, none of the cells are humans. Indeed, the cells have very few human traits, but the cells considered as a whole makes up a human. This example also shows that the selbri following loi must be satisfied by the members of the mass, but not by the mass itself: a human isn't a cell either.
A mass made with lei, such as lei gerku, refers to a mass formed by a group of specific individuals, which the speaker refers to as le gerku.
It needs to be noted that regular sumti built using lo are usually sufficient even when a selbri is meant to apply collectively. Constructing masses is mainly necessary when talking about multiple groups of individuals.
- sruri = x1 flanks/encircles/encloses x2 in line/plane/directions x3
lo prenu cu sruri lo zdani – People surround the house. The Lojban sentence shares the obvious meaning of the English one, namely that people are arranged around the house, not necessarily that individual people are stretched around it.
But what if we want to explicitly say that people surround the house from head to toe? In order to be explicit about a selbri distributing across individuals, one needs lo, le or la with an outer quantifier. The subject of quantifiers will be considered later, in lesson twenty-two.
Lastly, there are the (only two) generalizing gadri:
- lo'e = gadri: veridical convert selbri to sumti. Sumti refers to the archetype of lo {selbri}.
- le'e = gadri: Descriptive convert selbri to sumti. Sumti refers to the described/perceived archetype of le {selbri}.
Of which there is no la-equivalent.
So, what is actually meant by the archetype? For lo'e tirxu, it is an ideal, imagined big cat, which has all the properties which best exemplifies big cats. It would be wrong to say that this includes having a striped fur, since a big systematic subgroup of the members of the set of big cats do not have striped fur, such as the leopards and the jaguars. Likewise, the typical human does not live in Asia even though a lot of humans do. However, if sufficiently many humans have a trait, for instance being able to speak, we can say:
- kakne = x1 is capable of doing/being x2 under circumstance x3
lo'e remna cu kakne lo nu tavla - The typical human being can speak.
le'e then, is the ideal object as perceived or described by the speaker. This need not be factually correct, and is often translated as the stereotype, even though the English phrase have some unpleasant negative connotations, which the Lojban does not. In fact, everyone has a stereotypical archetypichal image of any category. In other words, lo'e remna is the archetype which best exemplifies all lo remna, while the archetype le'e remna best exemplifies all le remna.
The eleven gadri can be seen in the diagram below.
| Generic | Masses | Generalizing | |
|---|---|---|---|
| Veridical | lo | loi | lo'e |
| Descriptive | le | lei | le'e |
| Name | la | lai | does not exist |
Note: Earlier, there was a word xo'e for the generic gadri. However, the rules and definitions for gadri were changed in late 2004, and the current set of rules on this topic, nicked xorlo has replaced the old way. Now, lo is generic, and xo'e is used as an elliptical digit (lesson nineteen). There are also gadri for building sets (lo'i, le'i, la'i), but they are exceedingly rare in post-xorlo usage.
Lesson 15: Lojban sumti 2ː KOhA3, KOhA5 and KOhA6
See what happens if I try to translate the sentence: Stereotypical people who can speak Lojban speak to each other about the languages they can speak:
- bangu = x1 is a language used by x2 to express x3 (abstraction)
le'e prenu poi ke'a kakne lo nu tavla fo la .lojban. cu tavla le'e prenu poi ke'a kakne lo nu tavla fo la .lojban. lo bangu poi lo prenu poi ke'a tavla fo la .lojban. cu se bangu ke'a
What we see is that the Lojban version is much longer than the English. This is primarily because the first, ridiculously long sumti is being repeated two more times in the Lojban text, while the English can refer to it by each other and they - much more efficiently. Wouldn't it be clever if Lojban somehow had mechanisms for doing the same?
It turns out it does, what a surprise! Lojban has a range of words called sumka'i meaning sumti-representatives. In English, we refer to them as pro-sumti, because they are essentially the same as the English pronouns, but with sumti instead of nouns. In fact, you already know ti, do and mi, but there are many more, so let's get learning. First, we want to put it into system. We can begin with the ones most familiar to English, and what you've already learned:
- ti = sumka'i: immediate ‘it': represents a sumti physically near the speaker'
- ta = sumka'i: nearby ‘it': represents a sumti some physical distance from the speaker OR close to the listener'
- tu = sumka'i: distant ‘it': represents a sumti physically far from the speaker and the listener.'
You can again recognize the i, a, u-sequence which pops up over and over. Some things might take some clearing up, though. Firstly, these sumti can represent anything which can be said to occupy a physical space. Objects, certainly. Ideas, certainly not. Events are accepted, but only to the extent they are restricted to a specific place - the Jasmin Revolution cannot be pointed at, but some bar-fight or a kiss might. Secondly, note that the distance is relative to different things for the different words: tu only applies if it's distant from both the speaker and the listener. In cases where the speaker and listener is far apart and the listener cannot see the speaker talking, ta refers to something close to the listener. Thirdly, it's all relative and context dependent. These three words are all problematic in written text, for instance, because the position of the speaker and listener is unknown to each other, and changes as time goes by. Furthermore, the author of a book cannot point to an object and express the pointing in the book.
Then there is a series called KOhA3, to which mi and do (and ko, but I won't write that here) belongs:
- mi = sumka'i: The speaker(s).
- mi'o = sumka'i: The mass of the speaker(s) and the listener(s) .
- mi'a = sumka'i: The mass of the speaker(s) and others.
- ma'a = sumka'i: The mass of the speaker(s), the listener(s) and others.
- do = sumka'i: The listener(s).
- do'o = sumka'i: The mass of the listener(s) and others.
These six sumka'i are more easily grasped in the below Venn diagram:
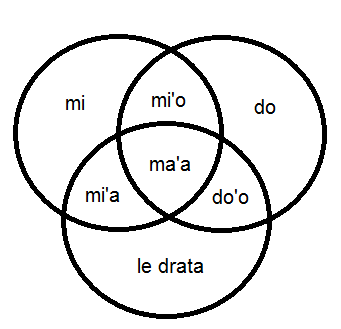
Venn diagram of KOhA3 (ko excluded). le drata is not a KOhA3, but means the other(s)
It is possible for several people to be the speakers, if one statement is made on the behalf of all of them. Therefore, while we can be translated as either mi, mi'o, mi'a or ma'a, what one quite often means is really just mi. All of these six, if they refer to more than one individual, represent masses. Within bridi-logic, the bridi mi gleki said by speaker A is exactly equivalent to do gleki said by speaker B to speaker A, and are considered the same bridi. We will come back to this later, in the brika'i (pro-bridi) lesson.
All of these sumka'i are very content-specific, and cannot be used, for instance, to help us with the sentence which this lesson began with. The following series can in principle be used to refer to any sumti:
- ri = sumka'i: Last sumti mentioned'
- ra = sumka'i: A recent, but not the last sumti mentioned'
- ru = sumka'i: A sumti mentioned long ago'
These sumti will refer to any terminated sumti except most other sumka'i. The reason that most other sumka'i cannot be referred to by these sumti, is that they are so easy to just repeat by themselves. The exception to the rule are ti, ta and tu, because you could have changed what you point at, and thus cannot just repeat the word. (There are some other exceptions, to be handled later.) They will only refer to terminated sumti, and thus cannot, for instance, be used to refer to an abstraction if the word in is that abstraction: le pendo noi ke'a pendo mi cu djica lo nu ri se zdani - here ri cannot refer to the abstration, since it is not terminated, nor to mi or ke'a, since they are sumka'i, so it refers to le pendo.
ra and ru are context-dependent in what they refer to, but they follow the rules mentioned above, and ru always refer to a more distant sumti than ra, which is always more distant than ri.
ri and it's brothers are pretty well suited for dealing with the original sentence. Try saying it using two instances of sumka'i!
Answer: le'e prenu poi ke'a kakne lo nu tavla fo la .lojban. cu tavla ru lo bangu poi ru cu se bangu ke'a. ri is not correct, because it refers to la .lojban.. ra could be used, but could be mistakenly be thought to refer to lo nu tavla fo la .lojban., but ru is assumed to refer to the most distant sumti - the most outer one.
Lastly, there a sumtcita which represent utterances: So called utterance variables. They need not be restricted to one sentence (jufra), but can be several sentences, if the context allows it:
- da'u = Utterance variable: Remote past sentence
- de'u = Utterance variable: Recent sentence
- di'u = Utterance variable: Previous sentence
- dei = Utterance variable: This sentence
- di'e = Utterance variable: Next sentence
- de'e = Utterance variable: Near future sentence
- da'e = Utterance variable: Remote future sentence
- do'i = Utterance variable: Elliptical utterance variable: Some sentence
These represents sentences as sumti, and refer only to the spoken words or the letters, not to the meaning behind them.
There are more Lojban sumka'i, but for now you probably need a break from them. The next lesson will be on derived sumti, sumti made from other sumti.
Lesson 16: Lojban sumti 3ː derived sumti
You can probably see that the sumti le bangu poi mi se bangu ke'a is a less than elegant expression for my language. This is because it's really a work around. A language which I speak can be said to fill into the x1 of the bridi bangu mi. We can't convert that to a sumti using a gadri: le bangu {ku} mi is two sumti, because bangu mi is a bridi, not a selbri. Neither can we convert it using le su'u, because the su'u gives the bridi a new x1, the abstraction, and the le then extracts that. That makes an abstraction sumti meaning something like that something is my language.
Enter be. be is a word which binds constructs (sumti, sumtcita and others) to a selbri. Using it in ordinary selbri has no effect: in mi nelci be do, the be does nothing. However, when a sumti is bound to a selbri this way, you can use a gadri on the selbri without the sumti splitting off: le bangu be mi is a correct solution to the problem above. Likewise, you can attach a sumtcita: le jinga be gau do: The one who wins because of you.
What if I want to attach several sumti to a selbri inside a gadri? The giver of the apple to you is le dunda be lo plise be do, right? Nope. The second be attaches to the apple, meaning le plise be do - The apple of the strain of you, which makes no sense. In order to string several sumti to a selbri, the all the ones following the first must be bound with bei. The binding can be terminated with be'o - one instance of be'o for each selbri which has sumti bound by be.
To list them:
- be = binds sumti or sumtcita to selbri
- bei = binds a second, third, fourth (ect) sumti or sumtcita to a selbri
- be'o = ends binding to selbri
There is also ways to loosely associate a sumti with another. pe and ne for restrictive and non-restrictive association. Actually, le bangu pe mi is a better translation of my language, since this phrase, like the English, is vague as to how the two are associated with each other.
pe and ne are used as loose association only, like saying my chair about a chair which you sit on. It's not really yours, but has something do to with you. A more intimate connection can be established with po, which makes the association unique and binding to a person, as in my car for a car that you actually own. The last kind of associator is po'e, which makes a so-called "inalienable" bond between sumti, meaning that the bond is innate between the two sumti. Some examples could be "my mother", "my arm" or "my home country"; none of these "possesions" can be lost (even if you saw off your arm, it's still your arm), and are therefore inalienable. Almost all of the times a po'e is appropriate, though, the x2 of the selbri contains the one to which the x1 is connected, so be is better.
- ne = non-restrictive relative phrase. "which is associated with..."
- pe = restrictive relative phrase. "which is associated with..."
- po = possesive relative phrase. "which is specific to..."
- po'e = inalienable relative phrase. "which belongs to..."
A very useful construct to know is {gadri} {sumti} {selbri}. this is equivalent to {gadri} {selbri} pe {sumti}. For instance le mi gerku is equivalent to le gerku pe mi. One could have description sumti inside description sumti, saying le le se cinjikca be mi ku gerku, = le gerku pe le se cinjikca be mi =the dog of the man I'm flirting with, but that's not very easy to read (or to understand when spoken), and is often being avoided.
One need also to learn tu'a, since it will make a lot of sentences much easier. It takes a sumti and converts it to another sumti - an elliptical abstraction which has something to do with the first sumti. For example, I could say mi djica lo nu mi citka lo plise, or I could let it be up to context what abstraction about the apple I desire and just say mi djica tu'a lo plise. One always has to guess what abstraction the speaker means by tu'a SUMTI, so it should only be used when context makes it easy to guess. Another example:
- gasnu = x1 does/brings about x2 (volition not implied)
za'a do gasnu tu'a lo skami - I see that you make the computer do something. Officially, tu'a SUMTI is equivalent to le su'u SUMTI co'e. Vague, but useful. There are situations where you cannot use tu'a, even though it would seem suitable. These situations are when I don't want the resulting sumti to be an abstraction, but a concrete sumti. In this case, one can use zo'e pe.
- tu'a = convert sumti to vague abstraction involving the sumti. Equivalent to le su'u SUMTI co'e kei ku
Finally, one kind of sumti can be turned into another by the words of the class LAhE.
- lu'a = Convert individual(s)/mass/sequence/set to individuals.
- lu'i = Convert individual(s)/mass/sequence/set to a set.
- lu'o = Convert individual(s)/mass/sequence/set to mass.
- vu'i = Convert individual(s)/mass/sequence/set to sequence; the order is not stated.
The use of these words is straight-forwardly: Placing them before a sumti of a certain type makes a new sumti of a new type. Notice, though, that as a fourth kind of sumti, a sequence has been introduced. This is not used very often (it doesn't have its own gadri, for instance), but just included here for completion.
The last two members of LAhE do not convert between types of sumti, but allows you to speak of a a sumti by only mentioning something which references to it:
If one sumti A refers to a sumti B, for instance because sumti A is a title of a book, or a name, or a sentence (which always refer to something, at least a bridi), la'e SUMTI A refers to sumti B. For instance, mi nelci la'e di'u for I like what you just said (not mi nelci di'u which just means I like your previous sentence) or la'e le cmalu noltru for the book The Little Prince, and not some little prince himself. The cmavo lu'e does the exact reverse – lu'e SUMTI refers to an object which refers to the sumti.
- la'e = "the thing referred to by" - extracts a sumti A from a sumti B which refers to A.
- lu'e = "the thing referring to" - extracts a sumti B from a sumti A, when B refers to A.
Lesson 17: Cute assorted words
And with that, third chapter, you know a lot about Lojban sumti. After such a long time of rigorous systematic learning, what could be more fitting that this lesson where I speak about some words which I could not, or wanted not to fit into any other lessons? So here are a few small and really useful words:
The following cmavo are all elliptical words. You should already be familiar with the first.
- zo'e = elliptical sumti
- co'e = elliptical selbri
- do'e = elliptical sumtcita
- ju'a = elliptical evidential
- do'i = elliptical utterance variable
- ge'e = elliptical attitudinal
All of these act grammatically as a cmavo of the kind they represent, but they contain no information, and can be quite handy when you're lazy and don't need to be specific anyway. There are, however, a few things which need to be cleared up:
- zo'e have to refer to something which is claimed to have a value. zero cars or nothing, for instance, has no value, and therefore cannot be referred to by zo'e. This is because, if it could mean nothing by zo'e, then any selbri could be identical to its negation, if one of the elided sumti were filled with a zo'e with no value.
- ge'e does not mean that you feel no emotion, just that you feel nothing special or worth to mention at the moment. It's similar to I'm fine.. ge'e pei ask about an elliptical emotion and is a good translation for: How are you feeling?.
- co'e is handy when needing a selbri in a construct for grammatical reasons, like in the definition of tu'a in the previous lesson.
- ju'a does not change the truth value or subjective understanding of the bridi or anything like that. In fact, it's mostly does nothing. However, ju'a pei, What is your basis for saying that? is handy.
- do'i is really useful. A lot of times when you refer to utterances or conversations by words like this or that, you want do'i.
- If you fill in more sumti than a selbri has places for, the last sumti have implied do'e sumtcita in front of them.
Furthermore, there is a word, zi'o, that you can fill a sumti place with to delete it from any selbri. lo melbi be zi'o, for instance, is just Something beautiful, and does not include the usual x2 of melbi, which is the observer who judges something to be beautiful. Thus, it can mean something like Objectively beautiful. It does not state that nothing fills the sumti place which is being deleted, just that the sumti place is not being considered in the selbri. Using zi'o with a sumtcita gives weird results. Formally, they should cancel each other out. Practically, it would probably be understood as an explicit way of saying that the sumtcita does not apply, as in: mi darxi do mu'i zi'o - I hit you, with or without motivation.
Then there is the word jai. It's one of those cool, small words which are hard to grasp, but easy to work with once you know it. It has two distinct, but similar functions. Both have something to do with converting the selbri, like se does.
- jai = Selbri conversion: Converts sumtcita or unspecified abstraction to x1. Use with fai
- fai = Marks sumti place. Works like fa. To be used with jai.
The first grammatical construction it can make is "jai {sumtcita} {selbri}". It changes the sumti places such that the sumti place of the sumtcita becomes the selbri's x1, and the selbri's old x1 is removed, and only accessible by using fai, which works like fa. You can see it with this example:
- gau = sumtcita (from gasnu) bridi has been brought about by/with active agent {sumti}'
do jai gau jundi ti fai mi. - You bring about attention to this by me. The new selbri, jai gau jundi, has the place structure of x1 brings about attention paid to x2. These are then filled by do and ti. The fai then marks the place for the old x1, the one who was paying attention, and it is filled with mi. This word can be very convenient and has tons of uses. A good example is descriptive-like sumti. One can, for instance, refer to the method of volitional action by lo jai ta'i zukte.
- ta'i = sumtcita (from tadji): Bridi is done with the method of {sumti}
Can you deduce what the ordinary Lojban phrase do jai gau mo means?
Answer: What are you doing?
The other function of jai is easier to explain. It simply converts the selbri such that the sumti in the x1 gets a tu'a in front of it (ko'a jai broda = tu'a ko'a broda). In other words, it converts the selbri in a way such that it builds an elliptical abstraction from the sumti in the x1, and then fills x1 with the abstraction instead of the actual sumti. Again, the original sumti place is accessible by fai.
A very active Lojban IRC-user often says le gerku pe do jai se stidi mi, to use a random example of a sumti in x1. What's he saying?
- stidi = x1 inspires/suggests x2 in/to x3
Answer: I suggest (something about) your dog.
So far you've learned how to convert bridi to selbri, selbri to sumti, and selbri into bridi, since all selbri by themselves are also bridi. You only need one last function: convert sumti to selbri. This is done with the word me. It accepts a sumti and converts it into a selbri.
- me = Generic convert sumti to selbri. x1 is/are among the referents of SUMTI
When screwing a sentence up, knowing how to correct yourself is a good idea. There are three words in Lojban which you can use to delete your previous word(s)
- si = deletion: Deletes last word only.
- sa = deletion: Deletes back until next cmavo spoken.
- su = deletion: Deletes entire discourse.
The function of these words are obvious: They delete words as if they have never been spoken. They do not work inside certain quotes (all quotes except lu...li'u), though, as that would leave it impossible to quote these words. Several si in a row deletes several words